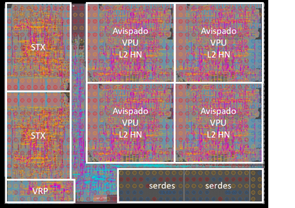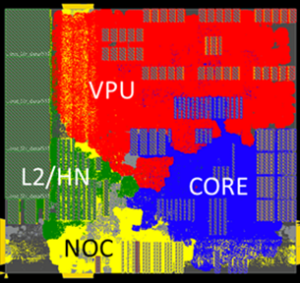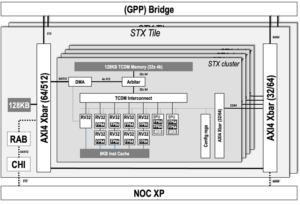
The VRP Tile enables efficient computation in scientific domains with extensive use of iterative linear algebra kernels, such as physics and chemistry. Augmenting accuracy inside the kernel reduces rounding errors and therefore improves computation’s stability. Contemporary solutions for this problem have a very high impact in memory and computation time (e.g. use double precision in the intermediate calculations), thus validating the motivation for specialized hardware acceleration.
The hardware support of variable precision, byte-aligned data format for intermediate data optimizes both memory usage and computing efficiency. When the standard precision unit cannot reach the expected accuracy, the variable precision unit takes the relay and continues with gradually augmenting precision until the tolerance error constraint is met. The offloading from the host processor, i.e. General Purpose Processor or GPP in EPI, to the VRP unit is ensured with zero-copy handover thanks to IO-coherency between EPAC and GPP.
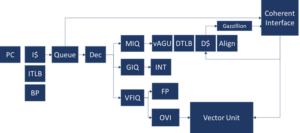
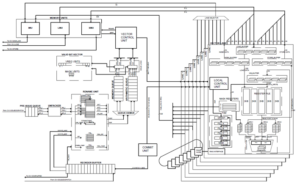
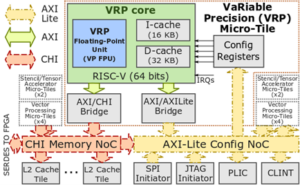
The VRP accelerator is embedded as a functional unit in a 64-bits RISC-V processor pipeline. The unit extends the standard RISC-V Instruction set with hardwired arithmetic basic operations in variable precision for scalars: add, subtract, multiply and type conversions. It implements other additional specific instructions for comparisons, type conversion and memory accesses. The representation of data in memory is compliant with the IEEE 754-2008 extendable format, which eases the integration with the GPP. The unit features a dedicated register file for storing up to 32 scalars with up to 512 bits of mantissa precision. Its architecture is pipelined for performance, and it has an internal parallelism of 64-bits. Thus, internal operations with higher precision multiple of 64 bits are executed by iterating on the existing hardware. The VRP micro-tile also features a high-throughput memory unit (load store unit and data cache) with a hardware prefetching mechanism, that hides the access latency to memory when running commonly memory-bound scientific applications.
The VRP programming model is meant for smooth integration with legacy scientific libraries such as BLAS, MAGMA and linear solver libraries. The integration in the host memory hierarchy is transparent for avoiding the need of data copy, and the accelerator offers standard support of C programs. The libraries are organised in order to expose the variable precision kernels as compatible replacements of their usual counterparts in the BLAS and solver libraries. The complexity of arithmetic operations is confined as much as possible within the lower level library routines (BLAS). Consistently, the explicit control of precision is exclusively handled at solver level.